1. 알고리즘 문제 해결
최소비용 구하기 2(백준 11779):
어제 풀었던 간단한 다익스트라 알고리즘에 추가로 각 노드별로 직전 노드만 저장했다가 역추적해서 경로를 찾아내면 되는 문제. 그래서 별 문제 없이 풀릴 줄 알았는데, 맞왜틀 주화입마에 빠져서 엄청 고생했다..

#include <iostream>
#include <vector>
#include <queue>
#include <algorithm>
#define INF 987654321
using namespace std;
struct cmp {
bool operator()(pair<int, int> l, pair<int, int> r) {
return l.second > r.second;
}
};
int main() {
cin.tie(nullptr);
ios_base::sync_with_stdio(false);
int n, m, start, target, cost;
cin >> n >> m;
vector<vector<pair<int, int> > > adjList(n+1, vector<pair<int, int> >());
for(int i=0; i<m; i++) {
cin >> start >> target >> cost;
adjList[start].push_back({target, cost});
}
cin >> start >> target;
vector<pair<int, int> > costs(n+1, {INF, 0});
vector<bool> isVisited(n+1, false);
costs[start] = {0, 0};
priority_queue<pair<int, int>, vector<pair<int, int> >, cmp > pq;
for(auto edge: adjList[start]) {
costs[edge.first] = {min(costs[edge.first].first, edge.second), 1};
pq.push({edge.first, edge.second});
}
isVisited[start] = true;
while(!pq.empty()) {
auto top = pq.top();
pq.pop();
if(isVisited[top.first]) continue;
if(top.first==target) {
deque<int> dq;
int node = target;
while(node!=start) {
dq.push_front(node);
node = costs[node].second;
}
dq.push_front(start);
cout << top.second << "\n" << dq.size() << "\n";
for(auto vertex: dq) {
cout << vertex << " ";
}
break;
}
isVisited[top.first] = true;
for(auto edge: adjList[top.first]) {
if(!isVisited[edge.first]) {
if(costs[edge.first].first>costs[top.first].first+edge.second) {
costs[edge.first] = {costs[top.first].first+edge.second, top.first};
pq.push({edge.first, costs[edge.first].first});
}
}
}
}
}
이게 처음에 작성했던 코드인데, 메모리 초과가 뜨고나서 원인을 찾으려고 한참을 고생했다.
시도해 본 것:
- 심플하게 자료구조와 자료형 건들기(Int형에서 Short형으로 줄일 수 있는 것 줄이기, 근데 이거 때문에 마지막에 더 고생했다)
- 각종 변수들 전역변수로 빼보기(근데 이건 사실 메모리를 많이 차지하는 vector와 priority_queue 등의 경우, 결국 로컬 스코프엔 포인터만 존재하고 실질적인 내용물은 힙에 존재할테니 메모리 스택에는 영향이 거의 없었을 것이다)
- 성능을 위해 사용했던 isVisited 리스트 삭제 후, 맞춰서 알고리즘 조정하기(이것도 해봐야 1,001*1바이트라 큰 의미는 없었을 것이다)
- Vector capacity 오버하게 할당하는 것 제거하기(초기화를 이미 동적으로 초기화해서 의미가 있었을까 싶었지만, 혹시나 매번 size가 꽉찼을 때 capacity는 미리 두배로 확장하는 동적 배열의 확장 전략 때문에 영향이 있을까 싶었다), swap() 이용하는 방법이랑 shrink_to_fit()을 이용하는 방법 둘 다 해봤다.
아마 이 시점즈음부터 자료구조 쪽에는 문제가 없을 것 같다는 생각이 들었고, 다익스트라 알고리즘 내의 우선순위 큐가 터지는 것이라고 의심했던 것 같다.
- 다익스트라 알고리즘 개별 함수로 추출하기(스코프가 달라지면 채점할 때 메모리 상으로 유리한게 있나 싶었다)
- costs내에 pair로 다루던 것 따로 분리해서 실행해보기(이것도 capacity 상으로 이점이 있나 싶었다)
- 로직 들여다보기
- 로직 알아보기 쉽게 수정하기
- 로직 들여다보기
- 로직 들여다보기
- 로직 들여다보기
- 로직 들여다보기
- 로직 들여다보기
- 로직 들여다보기
...
아무리 고민을 해도 로직 상으로 문제가 없었다. 실수하기 좋은 부분들을 한참을 다시 본 것 같다. 우선순위 큐에 넣는 조건이나 시점, 각종 갱신하는 값들을 넣고 있는지, 초기 비용 값은 제대로 초기화 하고 있는지..
for(auto edge: adjList[start]) {
costs[edge.first] = {min((int)edge.second, costs[edge.first].first), 1};
pq.push({edge.first, edge.second});
}
문제가 된 건 이 단락이었는데, 뜬금없이 들어가있는 1이라는 숫자가 너무 어색했다. 무슨 생각으로 1을 넣은건지 모르겠는데 아마 처음에 예제를 보며 작성하다가, 시작 노드를 1로 고정해서 생각한 것 같았다. 진짜 체증이 싹 씻겨 내려가는 느낌이 들면서 이건 통과라고 확신했는데, 23%에서 틀렸습니다가 떴다.

코드를 뚫어져라 쳐다보니, 100,000까지 들어올 수 있는 변수를 내가 Short로 바꿔 둔 부분이 있었고 그걸 Int로 수정하자 끝내 통과할 수 있었다. 항상 맞왜틀 주화입마를 조심해야 한다.. 아래는 최종 제출한 코드.
#include <iostream>
#include <vector>
#include <queue>
#include <algorithm>
#define INF 987654321
using namespace std;
struct cmp {
bool operator()(pair<short, int>& l, pair<short, int>& r) {
return l.second > r.second;
}
};
vector<vector<pair<short, int> > > adjList; //node, cost
vector<pair<int, short> > costs; //costSum, prevNode
priority_queue<pair<short, int>, vector<pair<short, int> >, cmp > pq;
void dijkstra(int start, int target) {
for(auto edge: adjList[start]) {
costs[edge.first] = {min((int)edge.second, costs[edge.first].first), start};
pq.push({edge.first, edge.second});
}
while(!pq.empty()) { //node, cost
auto curNode = pq.top().first;
auto curCost = pq.top().second;
pq.pop();
if(curCost > costs[curNode].first) continue;
if(curNode==target) {
break;
}
for(auto edge: adjList[curNode]) {
auto nextNode = edge.first;
auto newCost = costs[curNode].first+edge.second;
if(costs[nextNode].first>newCost) {
costs[nextNode] = {newCost, curNode};
pq.push({nextNode, newCost});
}
}
}
}
int main() {
cin.tie(nullptr);
ios_base::sync_with_stdio(false);
int n, m, start, target, cost;
cin >> n >> m;
adjList.assign(n+1, vector<pair<short, int> >());
for(int i=0; i<m; i++) {
cin >> start >> target >> cost;
adjList[start].push_back({target, cost});
}
cin >> start >> target;
costs.assign(n+1, {INF, 0});
costs[start] = {0, start};
dijkstra(start, target);
deque<int> dq;
int node = target;
while(node!=start) {
dq.push_front(node);
node = costs[node].second;
}
dq.push_front(start);
cout << costs[target].first << "\n" << dq.size() << "\n";
for(auto vertex: dq) {
cout << vertex << " ";
}
}
2. 챌린지 반 과제
과제 자체는 본 과정 과제에 MVVM을 적용해 일부 리팩터링 하는 과제라서 금방 끝났다. 여유가 된다면 다음 주차 것도 시도해보라고 하셨는데, 아마 내일 시도해 볼 것 같다. 이것 말고도 튜터님께서 읽어봤으면 좋겠다고 한 글이 있어서 그걸 읽었다.
ViewModel 요청 과정을 보기 위해 by viewModels() 사용시 호출되는 코드가 링크되어 있었는데, 아무래도 과거의 코드는 deprecated 됐는 지, 특정 커밋 이후로 삭제된 듯 했다.

그래서 안드로이드 스튜디오에서 직접 확인하기로 했다.
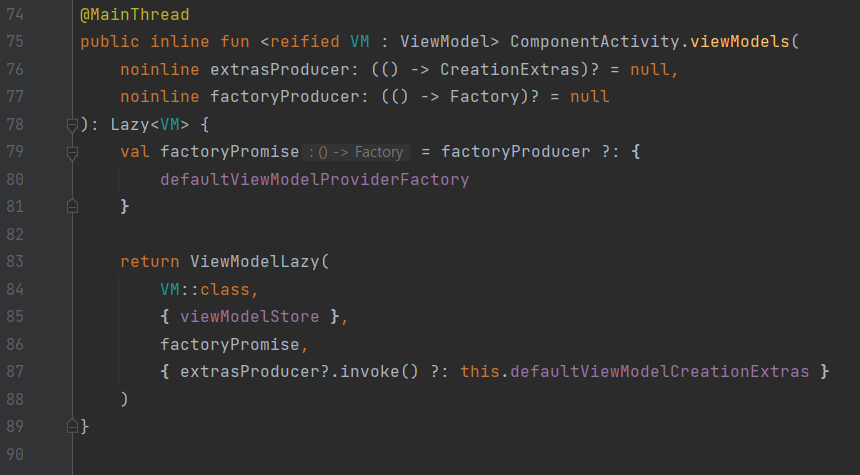

본문의 내용처럼 결국엔 ViewModelProvider를 이용해 생성하는 것을 확인했다.
이후에 저 ViewModelProvider.kt를 열어 확인해보니 완벽하게 이해한 것은 아니지만, ViewModelProvider 객체 생성해서 get을 통해 ViewModel을 요청하고, ViewModelStore 확인 후 없으면 Factory이용하는 것까지 대강 확인할 수 있었다.

또 ViewModelStore 내에서 clear()를 통해 ViewModel이 소멸되는 것도 확인했다. ViewModel의 대표적인 LifeCycle Owner라고 할 수 있는 ComponentActivity에서 실제로 액티비티가 Destroy 될 때, 실제 저 메소드를 이용해 ViewModel을 소멸 시키고 있었다.

본문의 내용들을 따라 직접 코드들을 찾아보면서, ViewModel의 LifeCycle에 대한 이해를 높일 수 있었다. 평소에 이런 부분까지 생각해보지는 않았는데, 이제 ViewModel이 어떤 방식으로 생성되고 관리되는지, 왜 LifeCycle Owner의 생명주기에 귀속되는지 알게된 것 같다.
'내일배움캠프 안드로이드 3기' 카테고리의 다른 글
| [TIL] 24.03.28 알고리즘, CS 리마인드 (0) | 2024.03.28 |
|---|---|
| [TIL] 24.03.27 알고리즘, 챌린지반 과제 (1) | 2024.03.27 |
| [TIL] 24.03.25 알고리즘, 사이드 프로젝트 등 (1) | 2024.03.25 |
| [TIL] 24.03.22 알고리즘, 사이드 프로젝트 (2) | 2024.03.22 |
| [TIL] 24.03.21 알고리즘, 사이드 프로젝트 (0) | 2024.03.21 |



