1. 앱개발 심화주차 개인과제를 하면서
오늘 TypeB까지 모두 마무리했다. 이번 개인과제는 혼자 여러 가지 고민들을 해보면서, 튜터님들께 질문을 많이 했는데 한층 더 실력이 성장할 수 있는 기회가 된 것 같다. 그동안 빠듯하게 개인과제와 챌린지반 과제를 진행하느라, 정리하지 못했던 고민들을 정리해두려고 한다.
❓ 클린 아키텍처에서 데이터를 직선적으로 받아오는 형태가 아니라면, 병합 등에 필요한 각종 로직들은 어디에 존재해야 하는가?
- 사실 이 부분에 대해서는, 아직까지도 확실한 결론은 내리지 못했다. 그도 그럴 것이, 튜터님들도 이건 상황과 취향에 따라 달라질 수 있는 부분이라고 하셨고, 나도 동의하고 있다. 아마 본인의 경험치가 가장 잘 나타나는 부분이 이런 부분이 아닐까 생각이 든다.
정답은 없지만, 의도와 근거는 명확한 상태로 선택하는 것이 중요해 보였다.
이번에 개인과제에서는 이벤트 발생시 네트워크를 통해 가져온 데이터와 로컬에서 가져온 데이터를 병합해서 보여줘야 하고, 로컬 데이터 변경점이 있을 때마다 실시간으로 UI에 반영되어야 했다. 나는 처음에 병합 로직의 위치를 고민했고, 먼저 UseCase 내에서 병합을 시도했다.
그런데, 로컬에서 가져오는 데이터는 DataStore로부터 Flow로 받아오고, 네트워크에서 받아오는 데이터는 검색이 발생할 때마다 단발성으로 가져오는 데이터였다. 이걸 병합을 하려다 보니, UseCase 내의 로직도 어떤 단일 기능만을 위한 비즈니스 로직의 범위를 벗어나고 있었고, 분명 검색을 할 때마다 불려야 하는 UseCase지만 반환 값은 Flow인 기형적인 형태가 되었다.
그래서 이는 ViewModel에서 검색 이벤트가 발생할 때마다 UseCase를 호출하고, 그 결과 Flow를 ViewModel 내에서 collect 해, View가 collect 중인 StateFlow에 다시 업데이트해줘야 하는 정말 지저분한 형태의 코드로 이어졌다.
이건 아니다 싶어서, 튜터님께 이런 문제를 설명드렸고 저번 글에서 작성했던 것처럼 UseCase를 세분화 했고, ViewModel 내에서 Flow api 이용해 combine 하는 것으로 리팩터링 하게 되었다. 변경 후의 코드가 훨씬 말끔했고, 각각의 부분이 좀 더 합리적인 책임을 갖게 되었다.
챌린지반 튜터님께서는 "해야 하나 싶으면 해야 한다, 번거롭게 느껴지는 작업이 있다면 그건 필요한 작업이다."는 뉘앙스의 조언을 자주 해주셨었는데, 요즘 그게 참 자주 와닿는 것 같다.
애초에 아키텍처니 디자인 패턴이니 하는 것도, 모두 유지보수 용이성이나 확장성 등 멀리 내다보고 기초 설계에 공을 들이겠다는 거니까, 이런 고민들에 시간을 많이 쓰게 되는 것도 어쩌면 당연하다고 생각한다.
이번 경험은 앞으로도 좋은 경험치가 돼 줄 것 같다.
❓ 클린 아키텍처에서 적절한 예외처리 시점?
- 이 내용도, 위의 고민과 어느정도 통하는 부분이 있다고 생각한다. data 레이어에서 발생할 수 있는 예기치 않은 예외들은 유저에게 적절하게 전달될 수 있어야 하고, 그래서 예외처리를 어떻게 할 것인지 많이 고민했다.
정말 예전에는 단순하게 data 레이어에서 예외를 잡아버리고, 미리 static하게 만들어둔 빈 entity나 에러 entity를 내려보내는 방식을 사용했었다. 이렇게 하면 이후 로직 전체에서 안전을 보장할 순 있지만, 어떤 예외가 발생한 것인지 presentation 레이어까지 전달하기가 어려웠다.
이후에는 domain 내에 Result 및 Error 클래스를 정의해두고, data 레이어에서 예외를 catch한 후 정의해 둔 Result로 래핑해서 내려보내는 방식을 사용했었다. Result는 sealed interface로 구성해 Sucess와 Error 형태로 필요한 프로퍼티 값들을 담아 내려보냈는데, 한동안은 이런 방법을 즐겨 썼던 것 같다. 이렇게 작성하면, presentation에서 예외 핸들링하는 것이 굉장히 편해진다. usecase의 실패 여부를 클래스 타입으로 바로 알 수 있고, Error 클래스를 잘 정의해 두고 이에 대한 확장함수를 구현해서 사용한다면, ViewModel 내에서 Error 타입에 대응하는 코드도 굉장히 줄어든다.
예를 들자면, Error 클래스 혹은 인터페이스의 msg 프로퍼티를 이용해, View에서 collect하는 ErrorEvent로 변환하는 확장함수를 구현해 주면, Error를 상속 혹은 구현한 모든 하위 Error 클래스들에 대해 ViewModel 내에서는 하나의 메소드로 처리할 수 있게 된다. 분기처리가 필요 없어진다.
대신 이렇게 하면, 래핑과 언래핑 하는 과정이 많아진다. 예전에 이런 Result 클래스는 불필요한 것 같다고 조언해 주시는 튜터님도 계셨고, 실제로 코틀린에서 지원하는 강력한 예외 핸들링 도구를 활용한다면 충분히 없앨 수 있는 래핑 과정이다.
그래서 이번에는 튜터님의 조언에 따라, data 레이어에서 예외를 감지해 throw 하면 ViewModel에서 이를 catch 하는 방법을 사용해 보았다. 그렇게 하더라도 domain에 ErrorModel 정도는 구현해 사용했는데, presentation에서는 발생한 예외가 직접적으로 어떤 클래스인지 몰라야 한다고 생각하기 때문이다. 가령 다중 모듈 앱을 구현한다고 쳤을 때, 네트워크나 DB를 위한 종속성은 data 레이어에만 implement 되어 있을 것이고, 그런 라이브러리들에 정의된 예외 클래스들은 presentation에서는 알 수가 없으니까.
이 때도 확장함수를 적절하게 이용했고, Result로 래핑하지 않아도 나름 깔끔하게 예외를 핸들링할 수 있다고 느낀 것 같다. 튜터님께서는 delegate 패턴에 대해 공부해 보고, coroutine을 커스텀해서 적용해 보면 보일러 플레이트 코드를 더 줄일 수 있다고 하셨다. 그래서 코틀린의 delegate 패턴을 공부해 봤는데, 아직까지 능숙하게 적용하기는 조금 힘든 것 같지만 좀 더 공부해 볼 생각이다. 상속과는 달리 composition 관계로 클래스를 구성하게 되는 느낌인데, OS에서 자주보았던 동적 모듈 개념과 맥이 통하는 부분이 있는 것 같다.
이후에 다른 튜터님께 이 부분에 대해 피드백을 요청드렸는데, 지금 패턴이 Result error handling 방식이랑 결이 비슷하다고, 그 부분에 대해서 공부해보라고 하셨다. 그래서 예전에 구현하던 Result 방식이 맞는 방식이었던 건가 또 고민을 하게 됐는데, 다시 공부해 보니 결국에는 선택의 문제인 것 같다.
얼마나 관용적인 코드를 작성할 것인가, 위험성을 언제부터 배제할 것인가, 얼마나 다양한 domain과 그 error가 정의되어야 하는가 등 여러가지 요소를 고려해봐야 할 것 같다.
대규모 프로젝트를 여러 번 경험해서 보는 시야를 넓히면 해결되는 문제라고 생각해서, 더 많은 경험을 쌓고싶다.
❓ 다중 모듈 앱에서의 종속 관계
- 이건 다중 묘듈 앱을 구현할 때 di 코드(정확히는 Hilt의 모듈)가 어디에 위치해야 하는지 고민하다가, 튜터님께 설명을 듣게 되었다. 왜냐면 나는 di 코드들을 app 모듈 쪽에 작성하곤 했는데, 그렇게 되면 di가 필요한 모듈들을 app 모듈에서 모두 알아야 하는 문제가 발생한다.
이게 뭔가 이치에 맞지 않다고 생각했다. app 모듈은 결국 종속성 피라미드 최상단에 위치하는 것이 맞지 않을까 하는 생각을 했는데, di를 app에서 구현하게 된다면(결국은 Hilt는 Application 기반으로 동작하니까, app 모듈에 위치할 수 밖에 없지 않나 생각한다), 분명 다른 모듈들이 알아야 할 모듈임에도 불구하고 역으로 app도 모두를 알아야 하는 꼴이 된다.
튜터님께서 실제로 Hilt를 사용하면 그런식의 종속 관계가 생긴다고 하셨고, 그런 상위 모듈이 하위 모듈을 알아야하는 구조의 단점과 그 상황 속에서 생길 수 있는 문제점들에 대해서도 설명해주셨다. 그래서 도입되는 것이 DFM으로, Dynaminc Feature Module 이라는 개념인데 이 것에 대해서도 공부해보라고 하셨다. 이걸 도입하면, 순수하게 하위모듈에서 상위모듈을 알아야 하는 구조를 이룰 수 있다고 한다.
그래서 구글에서 검색해봤지만, 아직 국내에서 적극적으로 도입되는 요소가 아닌지 관련 글이 많지는 않았다. 개념만 간단하게 찾아보니, 이것도 OS의 동적 모듈 개념이랑 유사한 느낌이 들었다. 이건 다음에 시간이 나면 관련된 레퍼런스가 있는지 좀 더 찾아보고 싶다.
❓ 스코프 함수 내에서의 this와 it
- 이번 과제를 하다가 원인을 알 수 없는 이슈가 발생해서 시간을 좀 썼는데, endless scroll을 통해 데이터를 추가적으로 load 해오면, 검색 결과의 일부가 중복되어서 나타났다. 정확히는 이전 페이지의 아이템들이 나타나는 것처럼 보였는데, 구조상 이런 버그가 발생할 부분이 잘 떠오르지 않았는데 아이템 중 일부만 그런다는 것이 유독 이상했다.
처음에는 새로 load 해 온 데이터들을 기존 데이터에 더하는 과정에서 logical error가 있나 싶어서, RecyclerView의 리스트 값이 변경될 때마다 adapter 내의 리스트의 아이템 갯수를 로그찍어 확인했는데 의도대로 정상적인 갯수 증가 양상을 보였다. 그래서 한참 해당 이슈를 재현하면서 관찰하다 보니, 이미지 아이템들에서만 그런 오류가 생기고 있다는 걸 발견했다.
그 때문에, 이번엔 API에서 뿌려주는 값 자체에 문제가 있나 싶어서, postman으로 해당 API를 한 페이지씩 넘기며 찍어봤는데 정상적인 순서와 내용으로 받아오고 있었다.


점점 더 의문만 늘었는데, 일단 load시에 문제가 발생하는 건 확실해보여서, 직접 ViewModel 내에 구현해 둔 페이징 로직과 loadMore() 메소드를 확인하기 시작했다. 디버거를 돌리며 한 줄씩 따라가다 보니, 이미지 API 결과 값만 1페이지 값을 계속해서 가져옴을 확인했고, 문제의 원인도 찾아냈다.
loadMore()이 호출되면 분명 정의해 둔 pagingMeta가 갱신되어야 하는데, pagingMeta의 이미지 관련 데이터는 전혀 갱신되지 않고 있었다. 해당 메소드는 pagingMeta가 null인지 확인하기 위해 pagingMeta?.let {} 블럭 내에서 로직을 실행하는데, 위의 이미지처럼 pagingMeta를 it을 copy해 갱신하고 있었다.
그런데 it이 pagingMeta를 직접 레퍼런싱 할 것이라고 생각했는데, 사실 그게 아니었던 모양이다. it이 가리키고 있는 것은 let 블럭이 호출되는 시점의 pagingMeta가 레퍼런싱 하고 있던 메모리 공간이고, 그 때문에 it을 copy하면 계속 원래 pagingMeta를 copy하고 있었다. 즉 내가 블록 내에서 pagingMeta를 갱신했지만(pagingMeta가 레퍼런싱 하는 주소 값 변경), it은 그 이전에 pagingMeta가 가리키고 있던 메모리 공간을 계속해서 지칭하는 상태인 듯 했다.
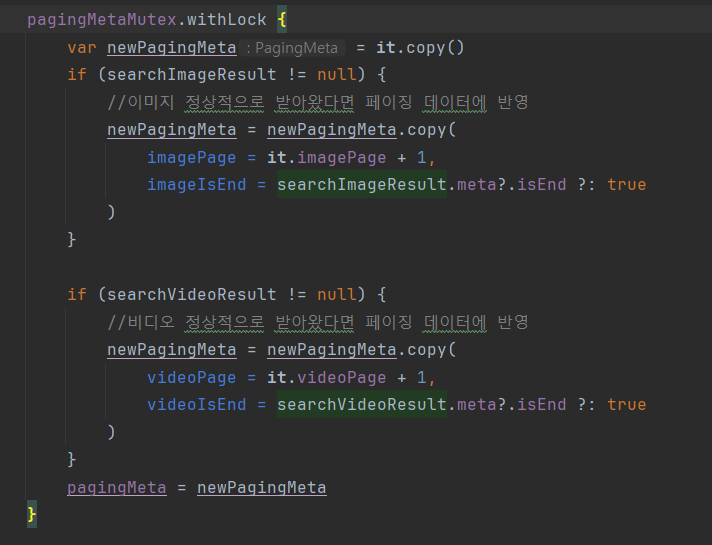
그래서 이런 식으로 변경해보니, 이슈는 완전히 사라졌고 의도한대로 동작했다.
일단 내가 생각한 것이 맞는지 확실하지는 않아서, 과제를 제출 할 때 해당 부분에 대해 질문을 남겨놨고, 답변을 받게 되면 확실하게 알 게 될 것 같다.
'내일배움캠프 안드로이드 3기' 카테고리의 다른 글
| [TIL] 24.05.21 Service Locator 패턴 적용하기 (1) | 2024.05.22 |
|---|---|
| [TIL] 24.05.10 Delegate 패턴 적용해보기 (1) | 2024.05.12 |
| [TIL] 24.05.07 앱개발 심화 주차 개인과제 (3) | 2024.05.08 |
| [TIL] 24.05.02 알고리즘 (2) | 2024.05.02 |
| [TIL] 24.05.01 알고리즘, 몇 가지 질의응답 (1) | 2024.05.01 |

